

PointNet++是PointNet的升级版,按照++作者的说法,PointNet无法提取到局部特征,同时也不能处理点的密度不一致的问题,因此在PointNet的基础上,作者进一步丰富了网络层次。
++主要分为三个部分:采样、分组、提特征。首先是采样,相比PointNet暴力地将原始数据点直接塞到网络里,++将原始数据点进行采样、分组,以获得最能表现各局部特征的点。
一、基本步骤
1.采样
采样的方法,叫做最远点采样(Farthest Point Sampling, FPS)。采样分为三个步骤:首先是随机采样,在刚开始的时候,随机选取一个点作为第一个点;其次是迭代选择最远点,意思是,在未选取的点中,找到一个距离已经选取的点中最远的点;最后,直到选取 N' 个点即可。
2.分组
已经选取了N'个点,将这些N'个点作为球心,选取一个值作为半径,在这个球体以内的点作为一个组。这种方法叫做球体查询(Ball Query),还有一个可以替代的方法,就是K近邻算法(kNN)。
3.提取特征
如何提取特征?这就要用到上次的PointNet了,将上述处理过的数据输入到PointNet网络之中,输入的单位是按照第二步的分组。因为作者是参考了CNN的思想,每一次卷积都是提取一个感受野的特征。对于PointNet++来说,每一次对“感受野”的“卷积”,实际上就是用PointNet作为“卷积运算”、一个组就是“感受野”。
二、层次化
按照上述的三个步骤,可以将其层次化,形成三个网络层,组成一个基本的小模块,论文中称之为set abstraction
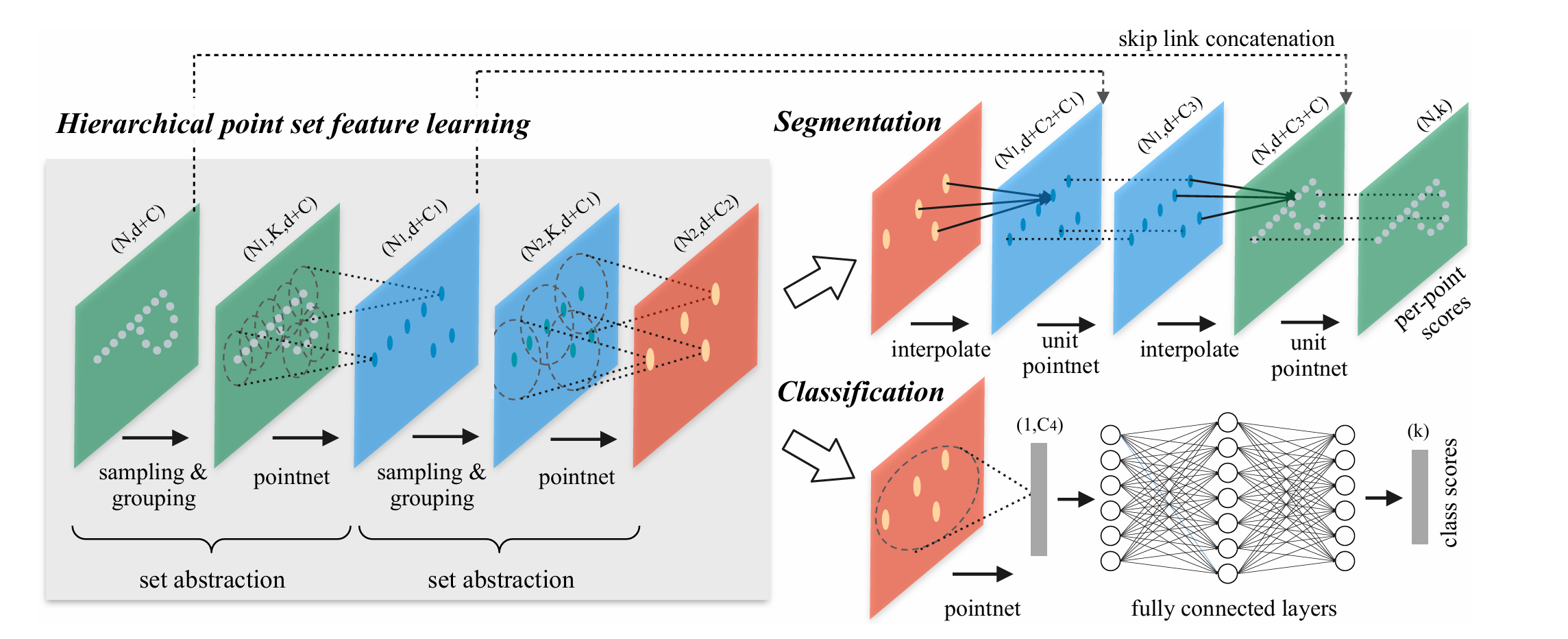
上图中左侧,每一层上有一个括号,其中N代表点的数量,d代表d维坐标,C代表C维点特征向量,K代表一个邻域中的点的数目。那么对于
$$ N' \times K \times (d + C) $$
来说,
$$ N' $$
代表的是组的数量,当然也可以理解为每组的几何中心点的数量,
$$ K $$
代表的是每组点的数量,d和C同上述描述一致。
三、点密度不均
原始数据的密度不均,会导致采样时存在采样不足,这样会使得整个网络对于信息的学习不足够。为了解决这个问题,作者给出了两个方法:MSG和MRG。
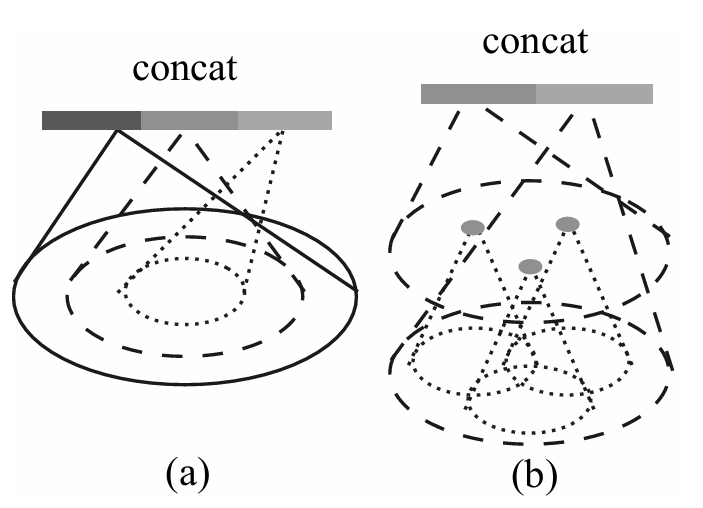
1.MSG(Multi-Scale Grouping)
上图的(a)即为MSG,可以看到这个方法的原理很简单,其实就是围绕一个中心点,拼接不同的半径下所提取的特征,形成最终的特征向量,方法是使用PointNet。这个方法还涉及到drop out,对于每一个点,都有$θ \in [0, p] where p<=1$的概率被丢弃,作者设置$p$为0.95,防止采样时采样到空集。
2.MRG(Multi-Resolution Grouping)
上图的(b)即为MRG,左边的特征向量来自对每一个组领域进行特征提取并总结得到的,方法是使用set abstraction;右边的特征向量来自将原始点通过PointNet网络后得到的特征。
四、点特征传播
这一部分,体现在PointNet++网络结构的右上部分。目的是:如何将网络学习到的抽象特征,精确地分配给原始点云中的每一个点。通过FPS降采样后,得到少部分点,后续的学习工作都是围绕这少部分的点展开的。对于分割任务,我们需要原始的每一个点,这样才能精细地将物品从背景中分离出来,因此就需要将学习到的特征分配给每一个点。
这其中包含两个机制:插值(Interpolation)和跨层跳跃连接(Across level skip links)。
对于插值,是要实现本层得到的特征,传播到上一层的点。方法是采用反距离加权平均 (Inverse Distance Weighted Average)。假设本层有1000个点,上一层有2000个点,要做的就是,对于每一个2000个点中的点P,要找到在1000个点中距离点P最近的k个点。将这k个点按照距离进行加权平均,距离越远,权重越小。将加权平均后的特征,作为点P的特征向量
对于跨层跳跃连接(Across level skip links),是为了上采用是不丢失细节,实现思想就是 //未完待续......